지난 포스팅에 이어 오늘도 Stable Diffusion WebUI의 메뉴설명 계속 가겠습니다. 메뉴가 복잡해서 설명할게 제법 되서 다 설명하려면 2번은 더 포스팅 해야될거 같군요.
탭메뉴 순서대로면 Img2Img 부터 설명해야되는데 결과물을 좀 만족스럽게 얻어가면서 진행하는게 좋을것 같아서 몇가지 많이 사용되는 플러그인 부터 설명하고 돌아오겠습니다.
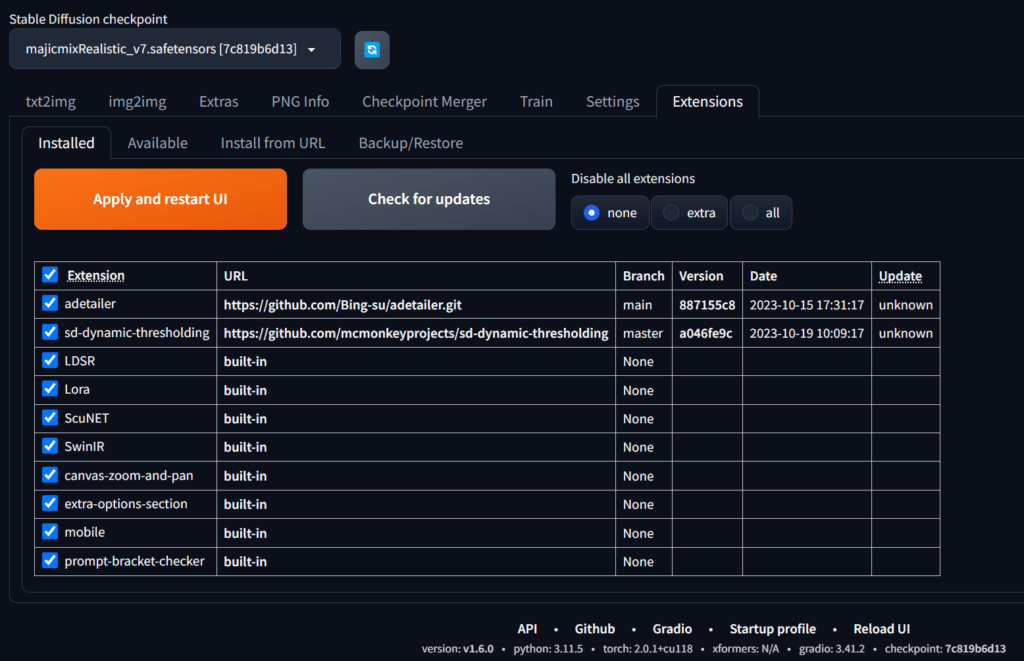
Tabmenu 맨 오른쪽에 보면 Extensions 라는 메뉴가 있습니다. 말그대로 확장기능입니다.
기본 기능 외에 개발자들이 참여해서 기능을 보완하고 새로운 기능들도 사용할 수 있도록 플러그인 기능을 추가할 수 있습니다.
좋은 플러그인들이 많이 있지만 ADetailer 플러그인만 추가하고 img2img 메뉴 설명으로 갈께요.
설치할 플러그인
1. ADetailer (After Detailer) : 얼굴 자동 수정
ADetailer(After Detailer)는 Inpaint를 자동으로 처리해주는 확장 플러그인입니다. 기존에는 Face Restoration 기능을 사용했지만 이를 많이 보완해줍니다.
Github을 통해 상세한 설명도 볼수 있습니다.
링크 : https://github.com/Bing-su/adetailer
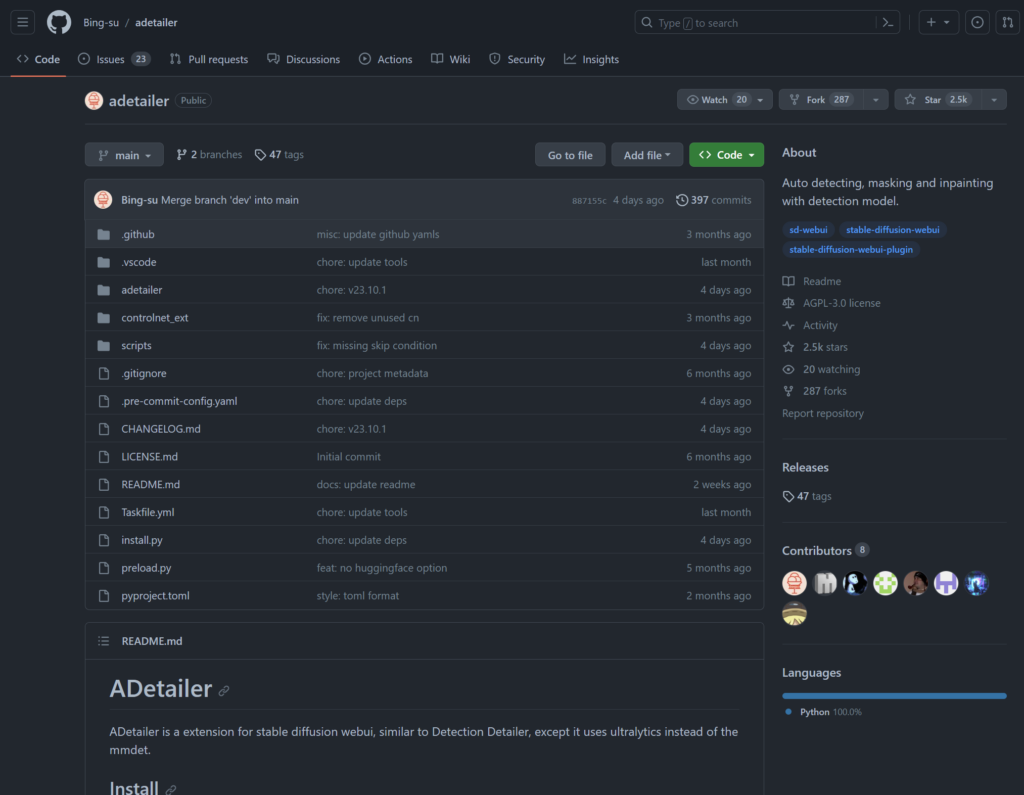
WebUI에서 Extensions > Install From URL 로 들어가서 “URL for extension’s git repository”밑에 입력창에 github 주소를 입력해줍니다. 밑에 “Specific branch name”하고 “Local directory name”부분은 그냥 비워두고 밑에 Install 버튼을 누르면 설치가 끝납니다.
https://github.com/Bing-su/adetailer.git
Installed 탭에서 “Apply and restart UI”버튼을 누르고 txt2img 메뉴로 돌아오면 Seed 밑에 영역에 ADetailer 라는 설정창이 생긴 걸 볼 수 있습니다.
그냥 “Enable ADetailer” 를 활성화 하는 것 만으로도 얼굴이 삐꾸가 되는 건 어느정도 막아줄 수가 있습니다. 원래대로라면 send to inpaint로 보내서 Mask처리하고 다시 생성하고 그런 과정들이 필요한데, 이 플러그인을 사용하면 자동으로 얼굴을 Detect해서 이런 inpaint처리를 자동으로 수행해줍니다.
이 플러그인이 왜 필요한지 아직 공감이 안될수 있어서 한가지 예를 보여드리겠습니다.
Adetailer 를 비활성화 하고 생성했을때 얼굴의 크기가 작은 결과물이라면 아래처럼 얼굴이 이상하게 나오는 경우가 있습니다. 이럴때 Enable ADetailer를 활성화하면 오른쪽 이미지 처럼 바로 수정이 된걸 확인할 수 있습니다.
지금 이렇게 이미지 만드는 방식은 지난 포스팅에서 알려드렸던 Seed값을 동일하게 넣어서 얻은 결과입니다. 운좋게도 거의 동일하게 얼굴만 고쳐졌네요. ㅎ


img2img 에서도 이 플러그인을 사용할 수 있는데 아직 설명을 안 한 관계로 다음 기회로 넘기도록 할께요. img2img 설명할때 함께 설명하겠습니다.
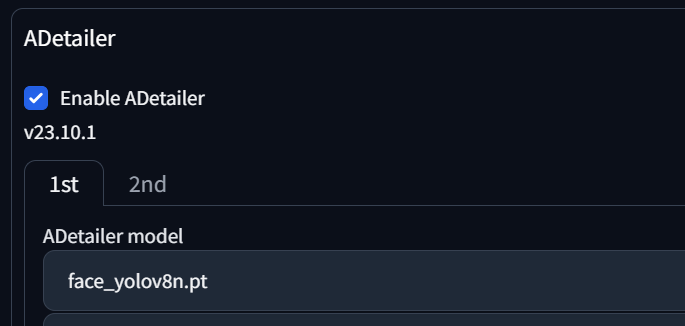
2. ADetailer 세팅화면
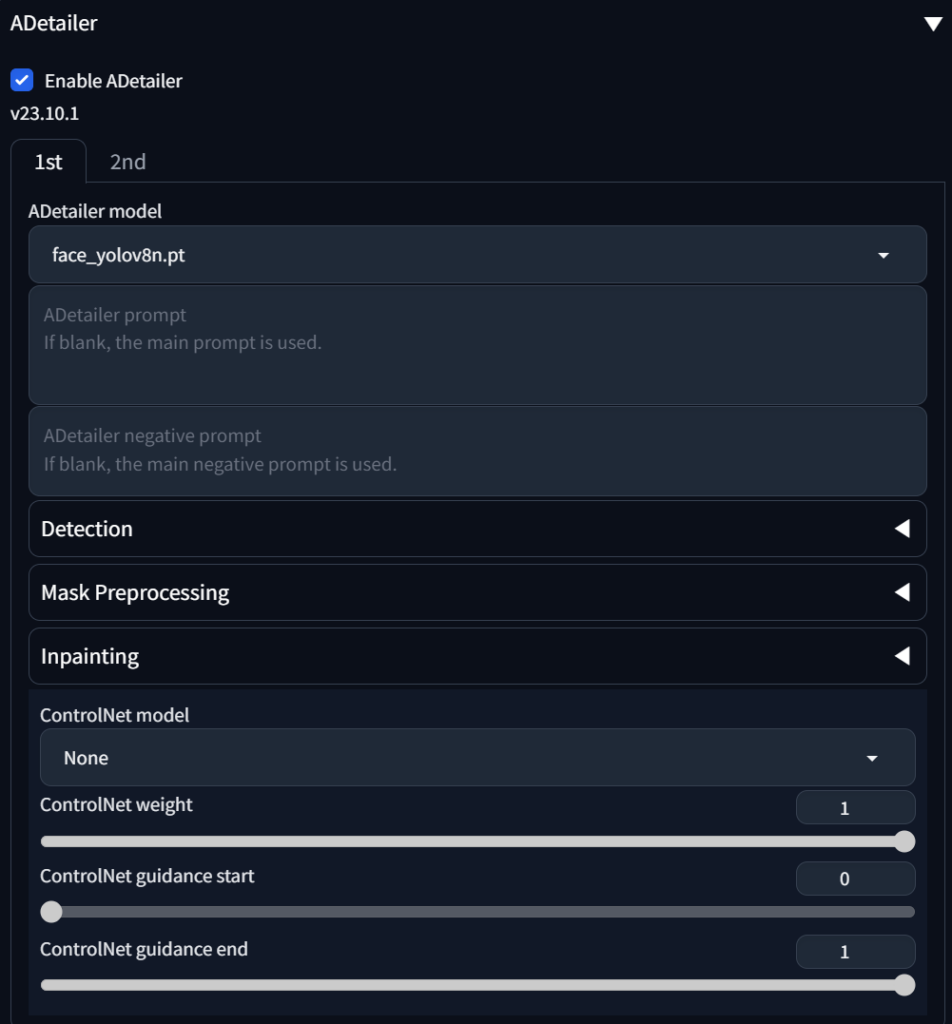
여기서도 Model 이라는게 등장합니다. ADetailer에서 제공하고 있는 Object Detection 모델 중 상황에 맞는 Model을 선택해주면 그 보정퀄리티가 좋아집니다.
Model (감지모델)
ADetailer Model 을 누르면 여러가지 선택할 수 있는 모델이 목록에 나옵니다.
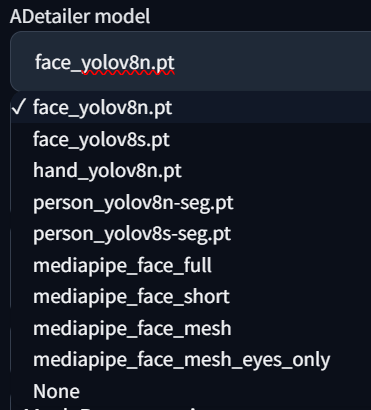
위와 같이 보여지는 모델은 크게 4가지 종류로 볼 수 있습니다.
- Face : 얼굴 감지 & 복원
- Hand : 손 감지 & 복원
- Person : 사람 전체 감지 & 복원
- Mediapipe_Face : 얼굴 감지 & 복원
사실 Face와 Mediapipe는 큰 차이를 체감하진 못했는데, Face모델을 사용하는 걸 추천하더라구요. YOLO 는 “You Only Look Once”라는 단어의 약자로 컴퓨터비전 분야에서 사용되는 실시간 Object Detection 시스템의 한 종류입니다. 객체 검출 기술 중에서 가장 대표적인 모델입니다.
더 깊게 들어가면 어려워지니 나중에 다시 설명하도록 하겠습니다.
Yolo 8n 과 8s의 차이는 성능 차이인데 n 이 더 빠릅니다. 하지만 빠르면 그만큼 품질이 떨어지는 건 어쩔수 없기에 시간이 충분하다면 8s로 쓰는게 좋을 것 같습니다.

만약에 얼굴도 이상하게 나오고 몸뚱아리도 이상하게 나오는 경우에는 1st / 2nd 탭에 각각 Model을 설정해주면 됩니다.
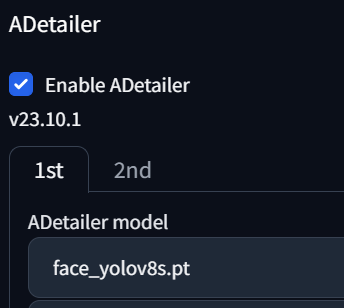
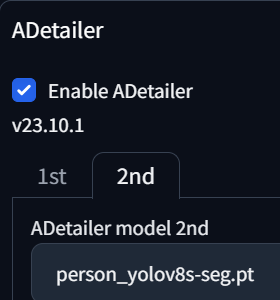
이렇게 설정하면 이미지를 일단 Generate 한 후에 Face보정이 되고 그 다음에 Person보정이 되는 순차적인 프로세스가 실행됩니다.
Prompt 추가 적용
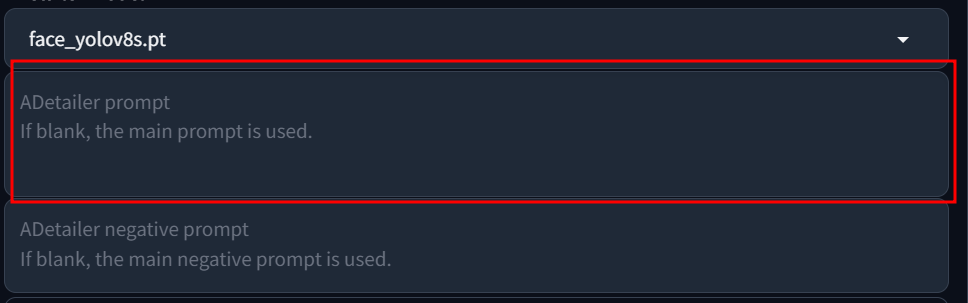
ADetailer 에서도 Prompt가 있는걸 보고 의아해 하시는 분도 계실텐데, 한번 생성된 이미지에서 얼굴만 Inpaint 로 다시 한번 처리하는 과정에서 이렇게 Prompt를 사용하면 얼굴에 해당하는 Prompt가 적용되는 겁니다.
예를 들면 연예인의 얼굴로 변경시킬수가 있는데, 프롬프트에 입력을 한번 해보도록 하겠습니다. 프롬프트 사용방법에 대해서는 이후에 자세히 포스팅할께요.
(Amanda Seyfried:0.8), Scarlett Johansson아 Model을 여러개 적용하는 경우에, Face를 1st로 하고 Person을 2nd 로 하는 경우에 얼굴 변경이 2nd 단계에서 다시 복원이 되는 상황이 있으니 모델의 순서를 조정해야될 수 있습니다.


이미지 생성에 입력하는 프롬프트에 연예인의 이름을 넣으면 한방에 되는거 아니냐고 말씀하는 분이 계실수도 있는데, 연예인들의 얼굴만 따로 학습시킨게 아니다보니 해당 키워드를 사용했을때 얼굴 외에 다른 부분까지도 결과물에 영향을 미치게 됩니다. 이를 Association Effect 라고 하는데, 이러한 이유 때문에 이미지를 생성한 후에 따로 Inpaint 처리하는게 좋습니다.
개인적으로는 이름을 직접 프롬프트에 넣는 방법 보다는 LoRA를 이용하는 방법을 선호하는데, 이는 이후 LoRA에 대한 포스팅에서 자세히 설명드리도록 하겠습니다.
CivitAI에서 이미지나 모델을 보다보면 Checkpoint, Checkpoint Merge, LoRA 등 의 표시가 되어있는걸 보셨을 겁니다. 이 중에 LoRA는 모델파일이 아니라 Adaptation 기법이 적용된 파일입니다.학습기법에 대해서는 이후에 Dreambooth, Textual Inversion 과 함께 설명하면서 원리와 사용법, 그리고 제작방법에 대해서도 알아보도록 할께요.
Detection
Model 밑에 Detection 이라는 메뉴가 보일겁니다. 말그대로 얼굴 혹은 신체를 감지하는 부분에 대한 설정 값입니다.
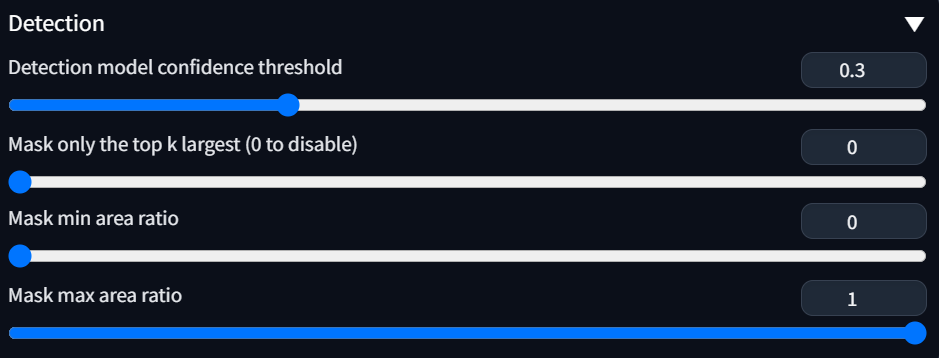
사실 어지간하면 건드리지 않는게 좋다고 생각하지만, 경우에 따라서 조금씩 수정을 해야할 수도 있어서 설명드리고 넘어가겠습니다.
- Detection model confidence threshold
- 얼굴을 Detection 할때의 신뢰도에 대한 설정입니다. 인식률이 떨어지는 이미지의 경우 얼굴인지 아닌지 구분을 못하는 경우가 있을텐데 이때 0.3 이라는건 Confidence Threshold(신뢰 한계)가 30% 신뢰한다는 의미입니다. 아마 더 높혀도 인식을 할수도 있지만 그냥 기본값으로 놔두어도 됩니다.
- Mask only the top k largest (0 to disable)
- Github에서 보면 이렇게 설명하고 있습니다. “Only use the k objects with the largest area of the bbox.”
- bbox는 bounding box의 약자로, 얼굴을 Detecting한 bbox가 여러개일수 있는데 그 중에 가장 큰 영역을 사용한다는 의미이고 기본값은 사용안함(disable)입니다.
- Mask min/max area ratio
- 감지하고자 하는 Object의 상대적인 크기의 비율을 의미합니다. 이 역시 기본값으로 사용하면 충분할 것 같습니다.
Mask Preprocessing
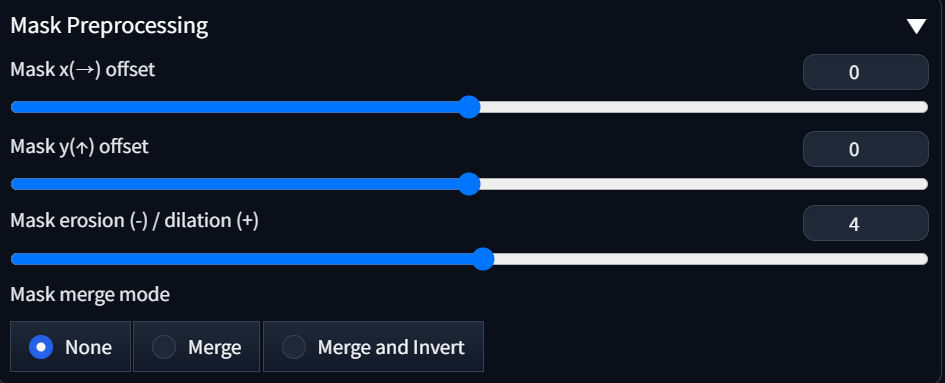
이 설정은 사용할일이 별로 없을거 같긴한데, Mask merge mode 만 알면 될거 같습니다. InPaint처리할때 자동으로 Detecting된 영역을 Mask로 전처리를 하는데 이때 영역처리를 어떻게 할지에 대한 옵션값입니다.
예를 들어 얼굴이 2개 탐지가 되었다면, Mask가 2개 생성되었을텐데 이때 각각의 Mask를 별도로 처리하려면 “None” 을 선택하면 되고, Merge는 한꺼번에 합쳐서 처리하고, Merge and Invert는 합친후에 그 바깥영역만 적용한다는 의미입니다.
Inpainting
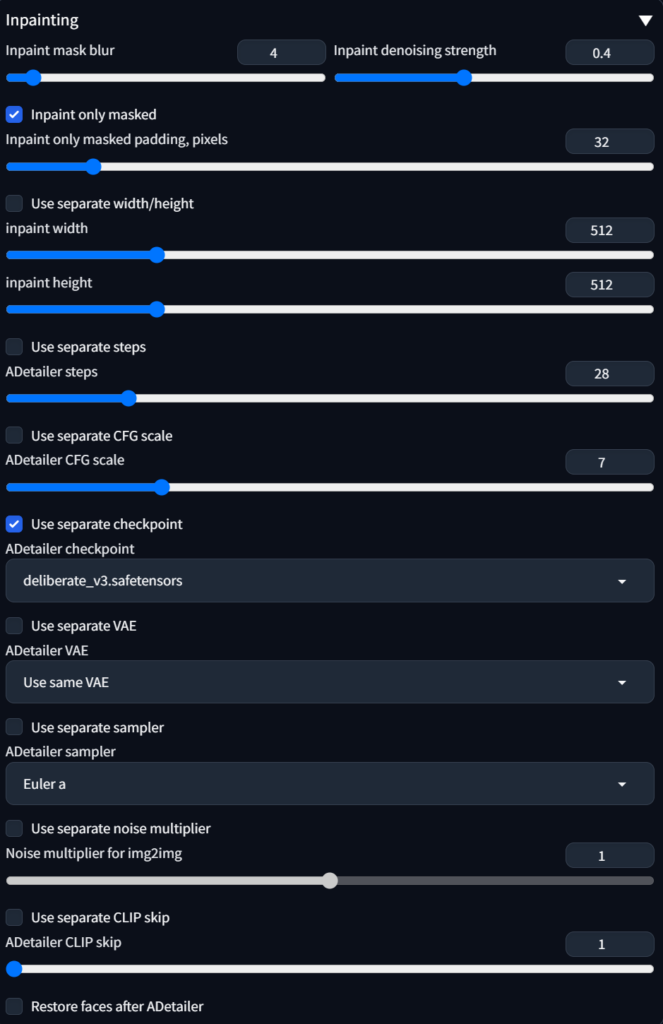
이 설정은 Inpaint과정에서 필요한 설정값입니다. 기본 이미지 생성 파라미터와 동일하게 사용하면 되는데, 반드시 켜놓아야 할 옵션은 “inpaint only masked” 활성화 입니다.
그 외에는 Inpaint denoising strength 값인데, 사용되는 noise제거에 대한 강도를 설정하는거라 값을 높히면 변화가 커집니다.
ADetailer checkpoint는 Inpaint에 다른 모델(checkpoint)를 적용하는 건데 동양인에 유리한 majic 모델에서 서양인으로 변경하고 싶어서 deliberate 모델을 적용했습니다.
ControlNet
이 설정은 아직 제가 다루지 않은 내용이라 이후 ControlNet을 다루게 될때 같이 설명하도록 하겠습니다.
기존 Face Restoration(얼굴 복원)기능은 기본탑재되어있는 CodeFormer, CFGAN같은 모델을 이용해서 복원을 하는데, ADetailer는 특정 영역을 감지해서 Inpaint를 수행하는 형태라 시간은 더 걸리지만 더 좋은 방식이라 생각됩니다.
반드시 이용하면 좋을 플러그인이라 메뉴설명 하다말고 먼저 설명드렸습니다.




{kind=link}