앞선 포스팅들에서 프롬프트들을 여러차례 살펴보았는데요. 공유된 프롬프트를 그대로 따라해도 너무 동떨어진 이미지 결과를 보게 됩니다. 이는 기본으로 적용한 모델(체크포인트)만으로는 무언가 설정이 부족하기 때문인데요. 이번 포스팅에서는 LoRA 라는 개념과 사용법에 대해서 알아보도록 하겠습니다.
LoRA 사용방법
개념 설명에 앞서서 어떤 차이점이 있는지부터 보도록 할께요. 우선 CivitAI 에서 개성이 강한 이미지를 찾아보겠습니다.

위의 이미지가 아주 특색있는 스타일인 것 같아서 샘플로 살펴보도록 하겠습니다.
LoRa에 대한 정보를 살펴보니 Base Model은 SD 1.5 입니다.
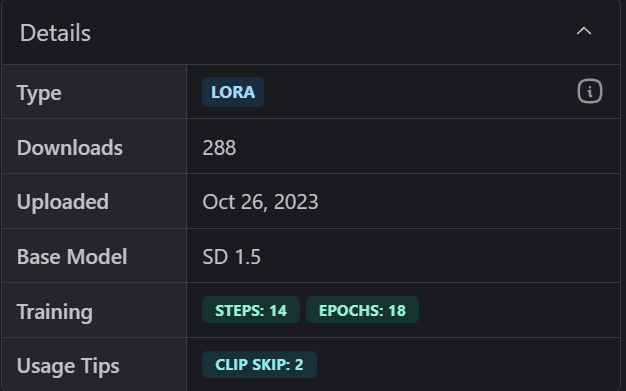
Keywords:
tornado, dreamy backdrop, waterfall, wind, cloud, reflection, floating, white flowers, drinking.
The above prompts can be used separately or in combination, with various effects, and you are free to experiment. By the way, this LORA is also an excellent model optimized for lighting effects.이렇게 알려주는 정보를 잘 살펴보고 프롬프트에 적용해야 합니다. 공개하고 있는 해당 LoRA 파일을 다운로드 받아줍니다. 그리고 SD설치폴더 > models > Lora 폴더에 넣어줍니다.
해당 LoRA가 SD 1.5 모델을 Base Model로 사용하고 있기 때문에 저는 이를 기반으로 하는 다른 Animation스타일의 모델을 사용해보도록 하겠습니다. 만약에 특정 모델을 Base로 하고 있는 경우에는 그 모델을 사용해줘야 더 근접하게 나옵니다.
masterpiece, best quality, 1girl, rain, wind, big breasts, tornado, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry위와 같이 Positive / Negative Prompt를 적어줍니다. 일단 LoRA 설정 없이 한번 생성해볼께요.
Animation스타일을 만들고 싶어서 AnythingV5 모델을 사용하겠습니다.

세팅은 이렇게 했으니 참고해주세요.


위의 이미지처럼 LoRA적용여부에 따라 차이점을 보이게 됩니다.
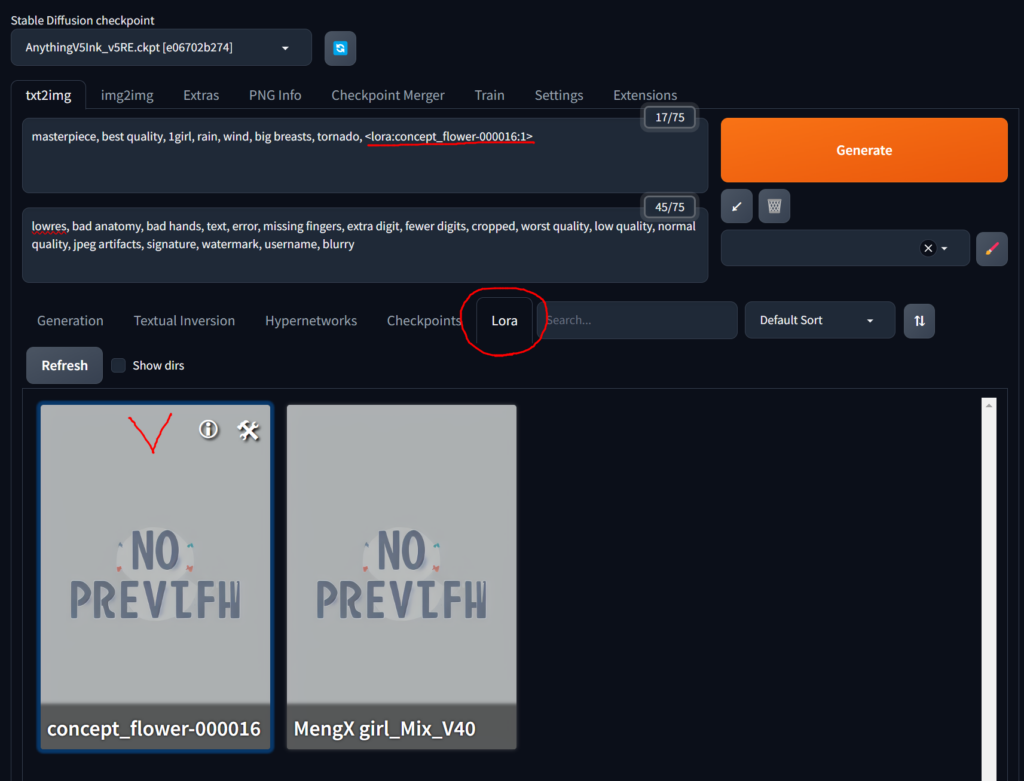
다운 받은 LoRA 파일을 {SD설치폴더} > models > Lora 폴더에 제대로 복사해두었다면 위에 화면처럼 Lora 탭에 나올겁니다. 사용하려는 Lora를 선택해주면 프롬프트에 반영됩니다.
LoRA를 프롬프트에 사용할때는 위와 같은 문법으로 사용하면 됩니다. 가중치값은 0~1 사이의 값인데, 낮을 수록 적용도가 낮아지게 됩니다. LoRA탭에서 선택해서 프롬프트에 입력하면 파일명을 외우지 않아도 됩니다.
LoRA는 생성하는 방법이 여러가지가 있는데, WebUI extension(d8ahazard), Kohya스크립트 등이 대표적입니다. 생성방법에 따라 Trigger Keyword를 적어줘야 하는 경우가 있는데요.

이런 경우에는 프롬프트에 해당 키워드를 적어줘야 구동이 됩니다.

그리고 LoRA는 여러개의 LoRA모델 여러개를 동시에 적용하는 것도 가능하고, Embedding과 함께 사용하는 것도 가능합니다.
이후 다른 포스팅에서 LoRA 생성방법과 LoRA 모델의 Merge 하는 방법 등도 소개해드리도록 할께요. 체크포인트처럼 LoRA도 Merge가 가능합니다. 다만 학습을 시키기 위해서 Dreambooth 같은 기능을 사용하려면 VRAM이 12GB 이상 되어야해서 사양이 높은 분들만 가능하니 이점 참고해주세요.
LoRA 모델
이렇게 같은 모델에서도 차이점을 만들어내는 LoRA 모델은 일반적인 checkpoint 모델에서 작은 변화를 만드는 모델입니다. 보통 체크포인트 모델은 1기가를 훌쩍 넘는 경우가 많은데, LoRA모델은 100메가 정도 수준인 경우가 많습니다.
LoRA는 Low-Rank Adaptation (for Fast Text-to-image Diffusion Fine-tuning) 의 약자로 파일 크기와 학습능력 간에 적당한 균형을 이루고 있습니다. 복잡한 데이터 분포에서 샘플링의 효율성을 향상시키는 역할을 합니다. 앞서 말씀드렸던 학습기법 중에 Embedding, DreamBooth 가 있었는데 그 중간 정도의 모델이라고 보시면 됩니다.
학습능력 : 드림부스 > LoRA > 하이퍼네트워크 > 임베딩
Dreambooth는 강력하지만 모델의 파일크기가 3-6기가 정도가 될 정도로 매우 큽니다. Embedding(Textual Inversion)은 파일이 1메가도 안될 정도로 작지만, 그만큼 성능이 떨어집니다.
LoRA모델은 단독으로 사용할 수 없고, 체크포인트와 함께 사용해야 됩니다. 해당 모델에서 작은 변화를 만들어서 스타일을 변형시키는 역할을 하기 때문입니다.
LoRA의 동작원리
간단하게 사용하는 방법은 위에서 설명했는데, LoRA를 만드는 방법을 설명하려면 동작원리에 대해서 간단하게라도 알고 넘어가는게 좋을 것 같습니다.
아래 이미지는 나무위키에서 발췌했습니다.

크게보면 Stable Diffusion은 CLIP, UNet 및 VAE(Variational Autoencoders)의 세 가지 인공 신경망으로 구성됩니다. 사용자가 텍스트를 입력하면 텍스트 인코더(CLIP)가 사용자의 텍스트를 UNet이 이해할 수 있는 token이라는 언어로 변환하고, UNet은 토큰을 기반으로 무작위로 생성된 노이즈를 제거합니다. 반복적으로 노이즈를 제거하면 적합한 이미지가 생성되고 VAE의 작업은 해당 이미지를 픽셀로 변환하는 것입니다.
해상도가 증가함에 따라 자원 사용량이 기하급수적으로 증가하는 이전 확산 확률적 이미지 생성 모델과 달리 오토인코더를 앞뒤에 도입하여 전체 이미지 대신 더 작은 차원의 잠재 공간에 삽입/제거합니다. 상대적으로 큰 노이즈 해상도 이미지를 생성하지만 노이즈 , 리소스 사용량이 크게 줄어들어 일반 가정용 그래픽 카드로 사용할 수 있습니다.
마치며
이번 포스팅에서는 LoRA에 대해서 살펴보았는데요. 다음엔 ControlNet 에 대해서 설명드리겠습니다. ControlNet도 개념상 LoRA와 비슷한 부분도 있지만, 여러분들의 간지러운 부분을 많이 해결해주는 다양한 기능이 있으니 기대해주세요.



{kind=link}